
초보를 위한 sql TIP
인 라인뷰
EMP Table을 참조하여 부서 평균 급여(소수점 반올림) 이상인
사람을 조회하는 SQL을 작성하되 급여 와
부서 평균 급여 차가 큰 사람순으로 나오도록 하시요
이러한 문제가 있다고 가정할 때
가장 문제가 되는 지점은
각 직원마다 부서별로 다른 평균이
적용되야 한다는 점이 골치 아플것이다.
직원마다 각 부서별의 평균을 따로 적용해야하니
emp테이블을 여러번 써야할것 같지만
인라인뷰를 이용하면 단두번만
이용하면 해결할수 있다.
SELECT e.DEPTNO,e.empno,e.ename,e.SAL,trunc(a.avg_sal) as AVG_SAL
FROM EMP e, (select deptno, avg(sal) as avg_sal
from emp
group by deptno) a
WHERE sal > a.avg_sal
and e.deptno = a.deptno
order by abs(sal-avg_sal) desc;
이런식으로 아예 from 절에 내가 필요한 정보를 가져와놓고,
where으로 부서번호에 맞게 분리 시킨다.
그러면 각 부서별 평균과 그 직원의 월급을 비교할 수 있다.
특정값으로 order by 정렬
SQL에서 order by는 그 값(문자열, 숫자)에 맞게
테이블을 정렬해주는 문구이다. 허나, 내가원하는 값으로
예를 들면 직급으로 정렬을 해야한다면 어떻게 하는가
이럴때는 CASE WHEN을 사용한다.
예를 들어 단 JOB이 PRESIDENT,MANAGER,SALESMAN,ANALYST,CLERK 순으로 조회되도록 하시요.
이러한 문제 가있을 경우 order by 문에
order by (CASE WHEN job = 'PRESIDENT' THEN 1
WHEN job = 'MANAGER' THEN 2
WHEN job = 'SALESMAN' THEN 3
WHEN job = 'ANALYST' THEN 4
WHEN job = 'CLERK' THEN 5 END);이렇게 적어주면 된다.
not equi 조인
Equi 조인은 특정 테이블에 값이 같을때 작동한다
예)emp 테이블의 deptno과 dept테이블의 deptno
허나 이 조인은 값이 정확하게 맞을때만 작동이 된다.
내가 특정영역별로 조인을 할려고하면 다른방식을 써야하는데,
그게 바로 non equi 조인이다.
예를 들어
SALGRADE Table ,EMP Table을 참조하여
GRADE별 몇 명인지 조회하는 SQL을 작성하시요
(SALGRADE 테이블에 얼마에따라 어느 등급인지 정보가 들어가있음)
라는 문제를 풀때 non Equi 조인을 사용하여
select * from SALGRADE;
select grade,count(grade) from emp e, salgrade s
where s.losal <= e.sal and e.sal <= s.hisal
group by grade
order by grade;
이렇게 작성할 수 있다. 이러면 SALGRADE 테이블의
등급의 가장낮은 월급값에서 가장 높은 월급사이에 있는 월급값을
매칭 시킬수 있다.
Oracle Analytic Function(분석 함수)
- 아래와 같이 EMP Table을 참조하여
부서 평균 급여(소수점 반올림) 이상인
사람을 조회하는 SQL을 작성하되 급여 와
부서 평균 급여 차가 큰 사람순으로 나오도록 하시요
라는 문제를 인라인뷰로 emp 테이블에 두번 엑세스하여
해결하였다. 허나 Oracle Analytic Function을 사용하면
단 한번만 emp테이블을 액세스하여 문제를 해결할 수 있다.
Oracle Analytic Function는
하나의 그룹으로부터 여러 통계 값이나 계산된 값을 여러개의
행으로 반환하는 함수
분석함수용 그룹(윈도우)을 따로 지정하여 그 그룹을 대상으로 계산을 수행한다.
형식은
윈도우 함수 (파라미터1,파라미터2.......)OVER (
PARTITION BY 표현식
ORDER BY 표현식 [ASC|DESC]
)
위에 있던 문제를 이 분석함수를 이용해 풀어보면
SELECT DEPTNO,empno,ename,SAL, avg_sal
from
(select e.*,round(avg(sal) over(partition by deptno)) avg_SAL FROM EMP e)
where sal > avg_sal
order by abs(avg_sal) desc;
이렇게 된다.
from에 deptno별로(부서별로) 평균을 계산해 그값을
쏴주는 형태다.
NOT IN과 NOT EXISTS의 차이점
예를 들어 가상으로 not in을 쓴 SQL문, NOT EXISTS를 쓴 SQL문이 있다고 하자
SELECT *
FROM TEST! A
WHERE A.NO NIT IN (SELECT NO FROM TEST2)
SELECT * FROM TEST1 A
WHERE NOT EXISTS(SELECT 1 FROM TEST2 B WHERE A.NO = B.NO)이 둘의 차이는 NULL값이 나오냐 안나오냐에 있다.
NOT IN의 경우
where절의 조건이 맞는지 틀리는지를 찾는것이다.
그런데 NULL은 조인에 참여하지 않기때문에 결과에서 빠지게된다.
여기서 TEST1의 NULL값이 나오지 않은 이유는 IN 서브쿼리의
결과에 NULL유무에 영향을 받지 않는다
즉, TEST2의 NO컬럼에 NULL값이 없어도
TEST1의 NO컬럼의 NULL값은 결과에 나오지 않는다.
NOT EXISTS의 경우
EXISTS는 서브쿼리가 TRUE인지 FALSE인지 체크하는 것이므로
NOT EXISTS는 서브쿼리가 FALSE이면 전체적으로 TRUE가 됩니다.
서브쿼리에서 TEST1과 TEST2의 조인시 NULL은 결과에서 빠지게 됩니다.
이것은 서브쿼리를 FALSE로 만들게 되고
전체적으로 TRUE가 되어 TEST1의 NULL값이 결과에 나오게 됩니다.
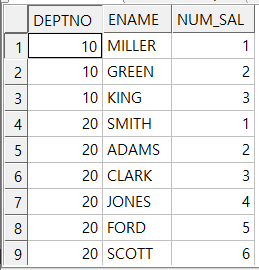
세로로 출력되는 데이터를 가로쓰기
3.부서별로 SAL 순으로 ENAME을 나열하는 SQL을 작성하시요.
라는문제 가 있다고하자 그러면 간단하게
select deptno,num_sal,ename
from
(select e.*,
count(empno)over(partition by e.deptno order by sal, hiredate) NUM_sal
FROM EMP e) a
order by deptno;이런 문장으로 처리할 수 있다.
허나, 세로로 나오는 데이터를 가로로 출력해야한다면 어떻게 할까
먼저 셀렉트 문을 잘 설계해보자 .
세로로나오는 데이터를 가로로 출력할려면, 셀렉트 절에 많은 인자가 들어갈 것이다.
select deptno,
decode(num_sal,1,ename,null) as ename_1,
decode(num_sal,2,ename,null) as ename_2,
decode(num_sal,3,ename,null) as ename_3,
decode(num_sal,4,ename,null) as ename_4,
decode(num_sal,5,ename,null) as ename_5,
decode(num_sal,6,ename,null) as ename_6
from
(select e.*,
count(empno)over(partition by e.deptno order by sal, hiredate) NUM_sal
FROM EMP e) a
order by deptno;이것을 출력하면 빈칸이 중간에 끼어있긴하지만,
가로로 출력하는데는 성공한다.

그러면 이제 어떻게 빈칸을 없앨까
바로 그룹바이와, max함수를 사용한다.
select deptno,
max(decode(num_sal,1,ename,null)) as ename_1,
max(decode(num_sal,2,ename,null)) as ename_2,
max(decode(num_sal,3,ename,null)) as ename_3,
max(decode(num_sal,4,ename,null)) as ename_4,
max(decode(num_sal,5,ename,null)) as ename_5,
max(decode(num_sal,6,ename,null)) as ename_6
from
(select e.*,
count(empno)over(partition by e.deptno order by sal, hiredate) NUM_sal
FROM EMP e) a
group by deptno
order by deptno;이런식으로 출력하면 내가 원하는 값만 뽑아올 수 있다.

12달 뽑아오기
만약 1년의 12달을 출력해야한다면 어떻게 해야할까
일단 1에서 12까지 나오는 쿼리를 작성해야 할것이다.
이렇게 다른언어에서 반복문의 값 처럼 SQL문에서 사용할려면 level
을 쓰면 된다.
select
lpad(level,2,'0')
from dual
connect by level <= 12;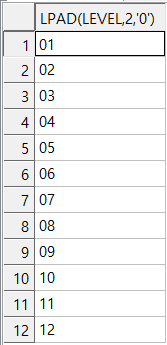
01부터 12까지 잘출력된다. 여기다 날짜 포멧을 붙이면
select
to_char(add_months(trunc(sysdate,'yyyy'), level-1),'yyyy/mm/dd') as saldate
from dual
connect by level <= 12
1년의 12달이 잘출력된다.
UNION
UNION은 세로로 결과를 합쳐주는 쿼리이다.
좀더 정확히 말하자면 select문의 결과 두개를 합쳐서 출력해준다.
그렇기 때문에 출력할때 컬럼의 갯수, 데이터 타입이 같아야한다.
UNION
그냥 UNION 이라고만 쓰면 중복은 제거된 채로 출력된다.
select empno,ename,job,sal
from emp
union
select empno,ename,job,sal
from emp;
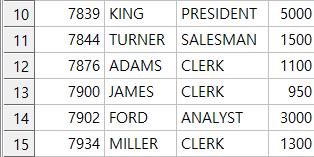
emp 테이블을 그냥 출력했을때와 같은 결과(15컬럼)가 나온다.
중복되는 값이 전부 짤렸기 때문
UNION ALL
UNION ALL을 사용하면 중복은 제거되지 않는다.
select empno,ename,job,sal
from emp
union ALL
select empno,ename,job,sal
from emp;

emp 테이블을 그냥 출력했을때와 다른 결과(30컬럼)가 나온다.
중복되는 값이 전부 보존되어 출력되었기 때문
UNION 응용
그렇다면 만약 '원하는 값하고만 합치고 싶다' 라는
생각이 들면 어떻게 해야할까
간단하다 null로 컬럼의 갯수를 맞춰주면 된다.
select empno,ename,job,sal
from emp
union all
select null,null,null,sum(sal)
from emp;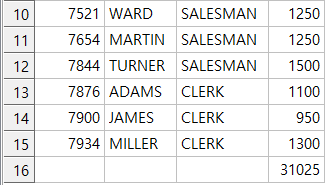
15개의 컬럼이 있는 emp 테이블에
sum(sal) 값 단하나만이 추가되었다.
중복된 값제거
만약 데이터를 인서트하다 완전이 똑같은 값이 들어갔을 때
(pk 제약조건이 없다고 가정)
어떻게 해야 중복된 값을 delete할 수 있을까?
rowid를 사용하면된다.
rowid는 그 칼럼의 고유한 아이디로써,
칼럼마다 다른값을 지니고있다.
delete from emp_dup a
where rowid > (
select min(rowid)
from emp_dup b
where b.empno = a.empno
);
delete from emp_dup
where
rowid in (
select rowid
from (
select * from (
select row_number() over(partition by empno order by empno) as empnum
from emp_dup
)
where empnum > 1
)
);다음 열 지정
만약 지금 열의 값부터 다음열의 값까지를 출력하고싶다면
lead() 함수 를 쓰면된다.
예를 들어 , 'emp 테이블에서 한 열의 hiredate와 그 다음열의 hireadte를
출력하고 싶다.'
라고한다면
select hiredate,lead(hiredate) over(order by hiredate)
from emp;이렇게 쓸수 있을것이다.
이 함수는 partition by로 원하는 기준으로 group by 할 수 있고,
order by로 원하는 기준으로 정렬 시켜서 사용할 수 있다.
만약 다음열이 아닌 전열의 값이 필요하다면 똑같은 방식으로 LAG()함수를 쓴다.
다음열 지정 응용
아래와 같이 EMP Table을 참조하여 부서별,기간별 소속된 직원수를 구하는 SQL을 작성하시요
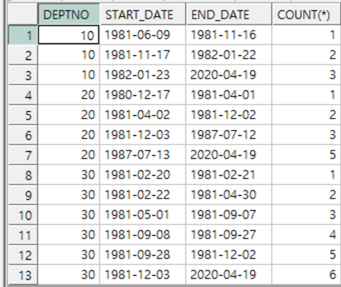
라는 과제가 있다고 치자
먼저 테이블을 보면, deptno으로 기분을 잡아 count를 한다.
허나, count도 start_date 즉, 한 사원이 입사하고 나서를 기준으로 잡아
기간별로 카운트를 한다.
즉, 카운트는 deptno,기간 이 두개의 기준으로 카운트가 된다.
둘째로 END_date 는 다음 입사한 사람의 hiredate에서 하루를 뺀값이다.
즉, lead함수를 응용해야한다.
select deptno, to_char( hiredate,'yyyy-mm-dd' ) as start_date,
to_char(
decode(
lead(hiredate) over(partition by deptno order by hiredate)
, null
, sysdate
,lead(hiredate-1) over(partition by deptno order by hiredate)
)
,'yyyy-mm-dd') as end_date,
sum(cnt) over(partition by deptno order by hiredate) as "count(*)"
from (
select ROW_NUMBER() OVER(PARTITION BY hiredate,deptno order by hiredate) as rnum
,count(distinct hiredate) over(partition by deptno,hiredate) as cnt
, emp.*
from emp
)a
where rnum = 1;먼저 deptno를 출력하고 , 그 다음 바로 hiredate를 형식에 맞게 출력한다.
그 다음은 END_Date ,END_DATE는 먼저 lead로 detpno으로 구분하고,hiredate로 정렬된 기준에서
다음 hiredate를 가져온다. 단, 가져올게 없으면 오늘 날짜가 들어간다.
가져올 데이터가 있으면 가져온 날짜 데이터에 하루를 뺀다 그리고나서
형식에 맞춰 출력한다. 이러면 END_DATE까지 끝났다.
허나 마지막 문제가 있다. 이 문제에서 중복값,
즉 deptno이 같으면서 hiredate가 같으면 중복으로 처리해 카운트 하지않는다.
이것을 해결하기 위해 중복된 값을 제거할 때 사용하는
ROW_NUMBER()함수로 hiredate,deptno이 같으면 number가 올라가게 설계하고,
where절로 rnum이 1인 값만 나오게 함으로써, 중복인 값이 카운트 되지 않는다.